Managing Data
The Big Picture
As participants submit their responses to your Study, Q-Assessor stores all of the data into its industrial-strength database at the back end. Q-Assessor lets you monitor your data as they come in via well-formatted tables.
Q-Assessor also lets you download your data in tab-delimited files that are easily imported into your application of choice — Excel, SPSS, SAS, R, or whatever. Most investigators will instead use Q-Assessor’s interactive, real-time analysis tools (discussed in the next section) to engage their results, but Q-Assessor makes it easy for investigators to utilize their data however they like.
Accessing Data
You can monitor the status of your data in real-time from your Study’s main page.
In the upper right corner of a Study’s summary page, the “Data” panel lists the number of participant Responses (the Q-Sort results) and the number of Interviews (the ancillary Question answers). Links in this panel lead you to pages where you can review both of these data sets in detail. |
|

Q-Sort Responses
A Study’s main Responses page displays all subjects’ submitted Q-Sort responses in a paged table. It also provides a variety of tools to use on the data.
The Q-Sort Responses table lists all subjects’ responses. The table’s columns include (as applicable) the subjects’ Subject Codes, their email addresses, their Q-Sorts, and the date they submitted their data. The “ID” under the Subject Code is a unique identifier for the specific response that enables you to merge Interview and Q-Sort Response data for anonymous subjects — discussed in detail below. |
|
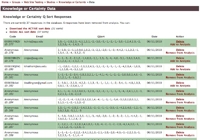
Q-Assessor provides a number of important tools for these data, linked to from this table. At the top of the page are links to Download the data (see below) and to Delete All the data (to be used very carefully, obviously, but important when you want to flush all the test data you’ve collected before releasing the study for real use).
You can also Delete a single response or Remove (or Add) it to the Q analysis. Of course, no one would ever cherry-pick their data, but Q-Assessor provides these features to let you deal with situations where someone may have submitted duplicate responses or otherwise made some error that you want to fix.
The ability to add and remove specific Q-Sorts from analysis does provide some interesting opportunities to investigate “what-if” scenarios as you explore your results. You can effortlessly include and exclude signal responses, then see immediately what effect they have on the detected Q factors. See the next section’s discussion of Q-Assessor’s real-time, interactive analysis capabilities for more on this.
Interviews
A Study’s main Interviews page displays all participants’ Interview question answers in a paged table and also provides similar tools to use on the data.
The Interviews table lists all subjects’ answers to the ancillary questions. The table’s columns include (as applicable) the participants’ Subject Codes, their email addresses, their question answers, and the date they submitted their data. The “Sort ID” under the Subject Code is a unique identifier for the specific Q-Sort response associated with these question answers. This link enables you to merge the Interview and Q-Sort Response data for anonymous participants — discussed in detail below. |
|

Like the Q-Sort Response tools, links in this table allow you to Download all the data in a tab-delimited file, Delete all the data (when you want to flush out test responses before releasing the Study for real use).
You can also singly Delete a participant’s answers and toggle them in and out of analysis — though since these ancillary questions are not part of the real-time, interactive Q analysis (see next section), this function is much less important.
Joining Q-Sort Responses and Interview Answers
Q-Assessor stores the Q-Sort Responses and the Interview Question data separately — because while the Q-Sort data will always have consistent characteristics, the ancillary questions can take any arbitrary form (number, content, etc).
Most Q studies focus primarily on the Q-Sort data and analysis per se, and only use ancillary data to interpret the Q factors that emerge from the sorts themselves. Consequently, the link between the two data sets is usually informally done post hoc. Further, the number of data points in a typical Q study is small enough (n=20-50, not 20-50K) that linking up sorts and interviews isn’t probably a big issue.
For studies with enrolled participants — so that both data sets have defined Subject Codes that identify the data in each set — this linking can be done easily. For studies that include anonymous participants — who do not have Subject Codes — Q-Assessor provides an alternate way to definitively link a given subject’s Q-Sort and Question answer data.
Each Q-Sort response has a specific ID that is displayed in the Subject Code column of the Responses table. Each corresponding Interview displays the “Sort ID” to which it is associated. Thus, if “Anonymous Joe” submits a sort that has “ID” = 123456789 in the system and continues on to submit ancillary question answers, those answers will have a “Sort ID” = 123456789. The “Sort ID” in the Interviews table will be equal to the “ID” in the Q-Sort Responses table for all sorts and interviews that belong together.
Q-Assessor leaves it up to the investigator to choose how she may want to merge these two data sets — which will depend on what other tools (Excel, SPSS, etc) they’re using as well as what their analysis plan is. However, Q-Assessor makes it easy for them to do, because the downloadable files include a “Sort ID” field where this unique identifier is always placed.
Downloading Data
As previously pointed out, at the top of a Study’s main Q-Sort Responses and Interviews pages are links that download all of their respective data in a tab-delimited file format. These files have these characteristics:
- The date/time of the download is included as part of the file name so that sequential data downloads will not inadvertantly overwrite each other.
- The first row of each file is a header that lists the fields of the subsequent data rows.
- Each row is a single subject data submission.
Once downloaded to your own computer, you import and merge these data files into whatever application you’re using. How you do this depends on your app and is beyond the scope of this discussion — but we are confident that if you’re doing Q research, you are very well acquainted with such tasks.
System Security and Privacy
Q-Assessor is a web application that runs at a leading hosting service. All operations within Q-Assessor are restricted to authorized users through a permissions system that checks user identity with each system access.
All data managed by Q-Assessor are stored in an industry-strength database on Q-Assessor’s server. Each study’s data are accessible only to authorized individuals:
- For individual studies, only the owner of the study can review, edit, download, or analyze the data. Individuals cannot access data belonging to other individuals’ studies or to groups studies of which they are not members.
- For group studies, only group members who have the necessary permissions can deal with the data. Groups cannot access data of other groups.
Q-Assessor staff can access studies including their data for the purposes of providing system support.
Study data collected via Q-Assessor can be completely anonymous or can capture precise identifying information about users — all depending on how the investigator configures his or her study:
- A study configured to allow anonymous responses and to omit any interview questions will be absolutely anonymous; there is no way to determine whose response is whose.
- A study configured to enroll known individuals will associate any Q sort data they submit with their email addresses — which obviously can be revealing or not, depending on what email service the study participant uses.
- A study that includes interview questions will solicit whatever type of information that the investigator decides to ask; Q-Assessor does not prevent investigators from asking personal information of any sort.
Participant consent is explicitly obtained for any study through a two-step process:
- The investigator presents in the “Study Intro” all information that a prospective participant needs to know about the study to determine whether they want to participate.
- The participant explicitly signals consent by clicking the “Start Study” button below the Study Intro in order to begin the study.
To date, all Institutional Review Boards (IRBs) have found these provisions satisfactory.
For further details about data security and privacy, see our Terms of Service.
Created: August 04, 2010 17:38
Last updated: June 26, 2015 17:18
Comments
No comments yet.
To comment, you must log in first.